#认识kafka
1、实时数据处理系统,最大的特点是服务解耦、流量削峰。
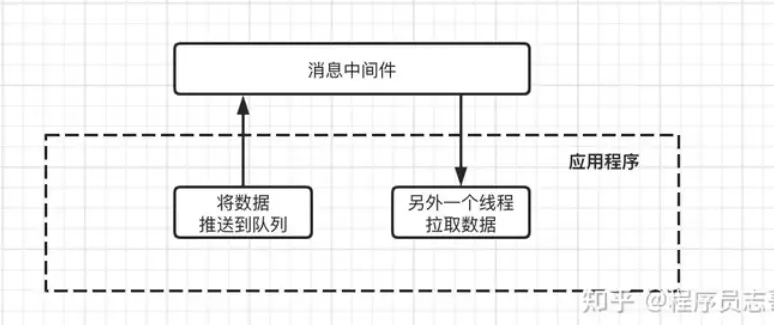
2、消息中间件:主要的职责就是保证能接受到消息,并将消息存储到磁盘,即使其他服务都挂了,数据也不会丢失,同时还可以对数据消费情况做好监控工作。
应用程序:只需要将消息推送到消息中间件,然后启用一个线程来不断从消息中间件中拉取数据,进行消费确认即可!引入消息中间件之后,整个服务开发会变得更加简单,各负其责。
3、Kafka 可以有效地处理每天数十亿条消息的指标和用户活动跟踪,其强大的处理能力,已经被业界所认可,并成为大数据流水线的首选技术。
#kafka的基础概念
概念一:生产者与消费者
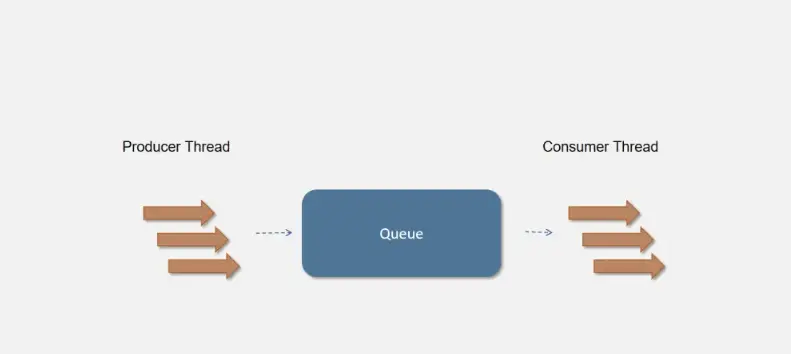
生产者-消费者是一种设计模式,生产者和消费者之间通过添加一个中间组件来达到解耦。生产者向中间组件生成数据,消费者消费数据。
在程序中我们通常使用Queue来作为这个中间组件。可以使用多线程向队列中写入数据,另外的消费者线程依次读取队列中的数据进行消费。模型如下图所示:
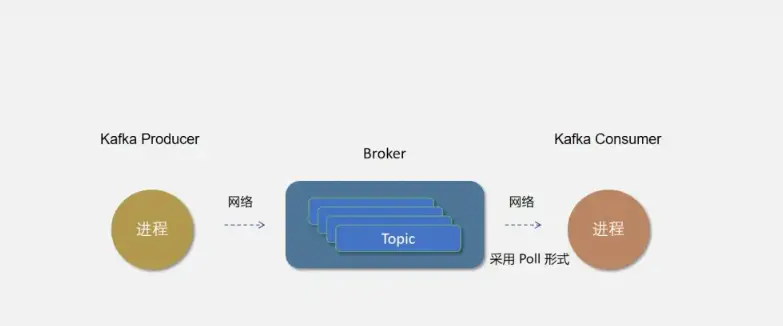
概念二:主题(Topic)与分区(Partition)
消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
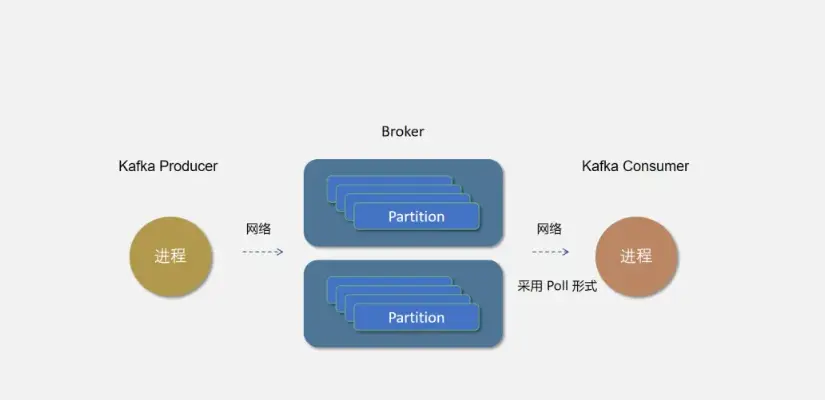
Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹。
这个分区的意思就是说,如果你创建的topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据。
这样做的目的,就是方便消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
概念三:控制器(Broker)和消费组(Consumer Group)
Broker:负责存储和处理消息,是Kafka服务器的一个实例,一个集群由多个Broker组成,每个Broker可以容纳多个Topic。
Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量。
基于消费组的概念,可以实现发布-订阅消息传递模式,生产者生成的数据会被持久化到一个Topic中,消费者可以订阅一个或多个Topic,消费者可以消费该Topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立即删除。
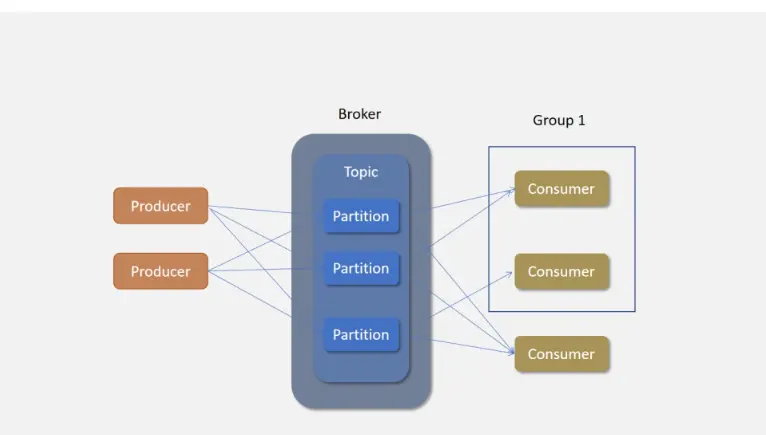
#kafka工作原理
先来看一张图,下面这张图就是 kafka 生产与消费的核心架构模型!
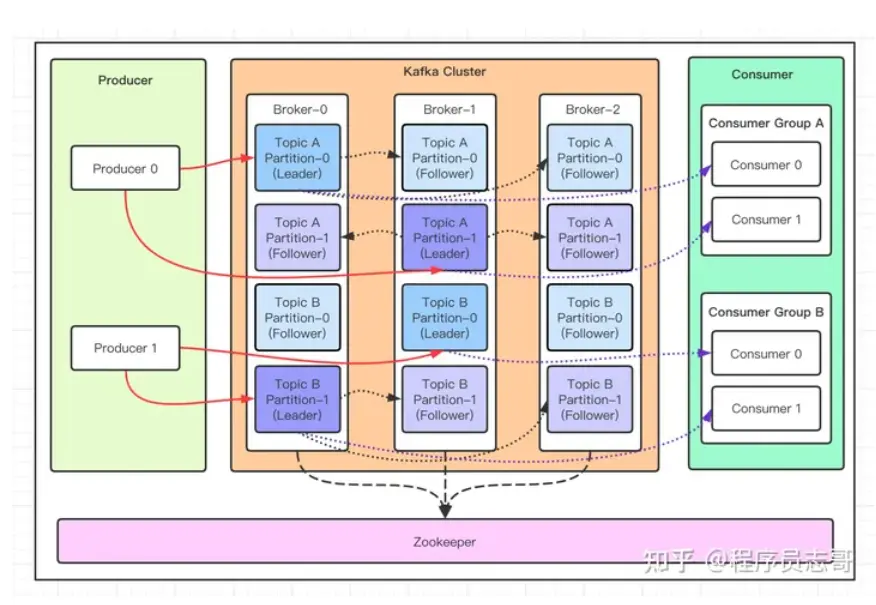
kafka 本质就是一个消息系统,与大多数的消息系统一样,主要的特点如下:
使用推拉模型将生产者和消费者分离
为消息传递系统中的消息数据提供持久性,以允许多个消费者
提供高可用集群服务,主从模式,同时支持横向水平扩展
发送消息
和其他的中间件一样,kafka 每次发送数据都是向Leader分区发送数据,并顺序写入到磁盘,然后Leader分区会将数据同步到各个从分区Follower,即使主分区挂了,也不会影响服务的正常运行。
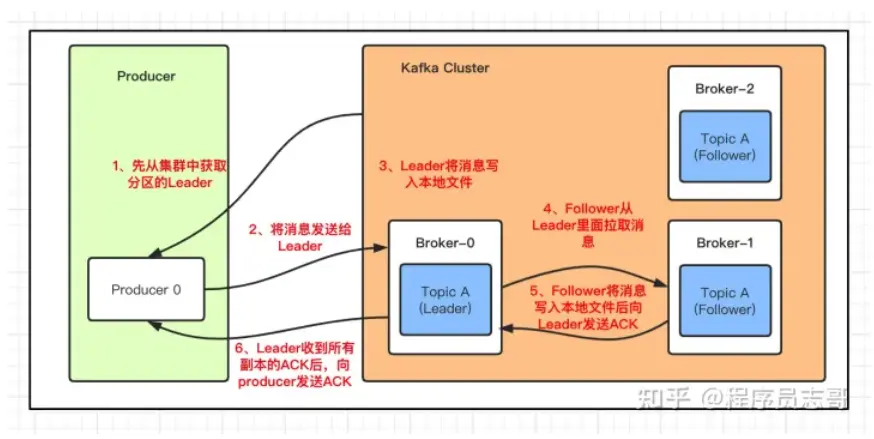
那 kafka 是如何将数据写入到对应的分区呢?kafka中有以下几个原则:
1、数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区
2、如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区
3、如果既没指定分区,又没有设置key,则会轮询选出一个分区
消费数据
与生产者一样,消费者主动的去kafka集群拉取消息时,也是从Leader分区去拉取数据。
这里我们需要重点了解一个名词:消费组!
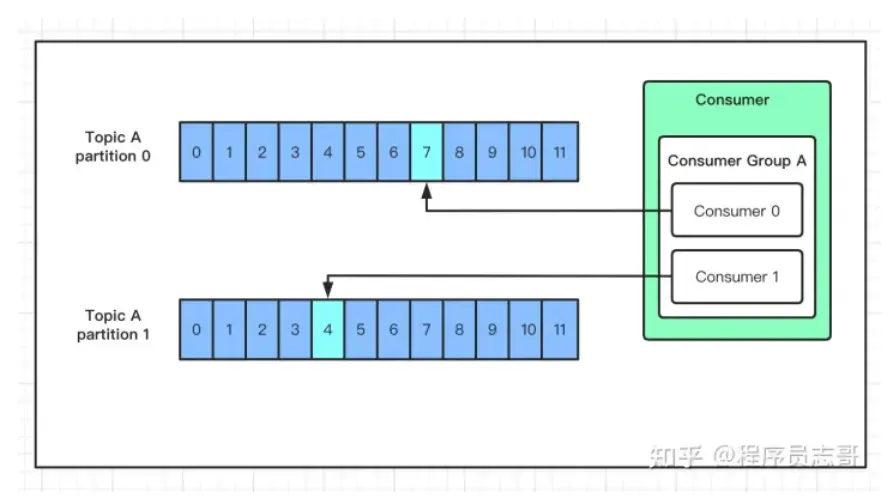
考虑到多个消费者的场景,kafka 在设计的时候,可以由多个消费者组成一个消费组,同一个消费组者的消费者可以消费同一个 topic 下不同分区的数据,同一个分区只会被一个消费组内的某个消费者所消费,防止出现重复消费的问题!
但是不同的组,可以消费同一个分区的数据!
你可以这样理解,一个消费组就是一个客户端,一个客户端可以由很多个消费者组成,以便加快消息的消费能力。
但是,如果一个组下的消费者数量大于分区数量,就会出现很多的消费者闲置。
如果分区数量大于一个组下的消费者数量,会出现一个消费者负责多个分区的消费,会出现消费性能不均衡的情况。
因此,在实际的应用中,建议消费者组的consumer的数量与partition的数量保持一致!